资讯
九游体育app娱乐每个MoE层包含128个群众和1个分享群众-九游(中国)jiuyou·官方网站-登录入口
发布日期:2025-12-18 09:05 点击次数:79
 智东西
智东西
智东西12月16日报说念,当天,英伟达推出了NVIDIA Nemotron 3系列绽开模子、数据和库,并公布Nemotron 3 Nano模子的工夫讲明注解。
Nemotron 3模子包括Nano、Super、Ultra三种界限,可匡助大界限开导并部署可靠的多智能体系统,完毕快速、长高下文推理。
emotron 3 Nano:领有300亿参数的袖珍模子,每次开动最多激活30亿参数,适用于针对性、高效的任务,主打高计较资本效益,展现了增强的智能体、推理和聊天才略,针对软件调试、本体摘要、AI助手使命流及信息检索等任务进行了优化。emotron 3 Super:领有约1000亿参数的高精度推理模子,每个token最多激活100亿参数,适用于多智能体应用,在需要多智能体融合完成低蔓延复杂任务的应用中证实出色。emotron 3 Ultra:领有约5000亿参数的大型推理引擎,每个token最多激活500亿参数,适用于复杂的AI应用,可行状于需要深度究诘和计谋方向的AI使命流。Nemotron 3系列模子引入了夹杂Mamba-Transformer MoE架构、跨交互式环境的强化学习、原生100万个token的高下文窗口,为多智能体应用完毕高蒙眬量、万古域推理。
该模子引入了多项改变,径直称心了智能体系统的需求:
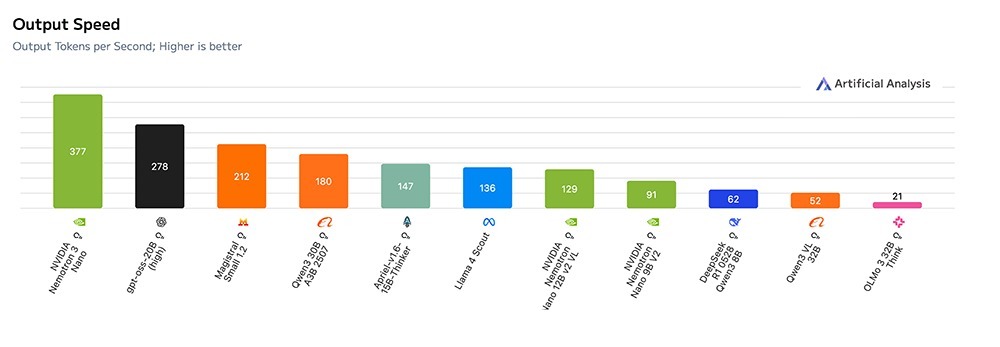
经受夹杂Mamba-Transformer MoE骨干网,完毕超卓的测试时辰效力和长距离推理才略。围绕果然寰宇的智能体任务联想的多环境强化学习。补助深度多文档推理和万古辰开动的智能体记念的100万个token高下文长度。一个绽开、透明的教化经由,包括数据、权重和配方。根据工夫讲明注解,比较雷同参数界限的绽开模子(如GPT-OSS 20B和Qwen3-30B-A3B-Thinking-2507),Nemotron 3 Nano完毕了多达3.3倍的推理蒙眬量。
Nemotron 3 Nano已上线Hugging Face平台,并通过Baseten、Deepinfra、Fireworks、FriendliAI、OpenRouter、Together AI等推理行状商提供。

Hugging Face地址:huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-FP8
emotron 3 Nano体验地址:build.nvidia.com/nvidia/nemotron-3-nano-30b-a3b
Nemotron 3 Super和Ultra展望将于2026年上半年推出。这两款模子经受了基于NVIDIA Blackwell架构的超高效4位NVFP4教化模式和改变的潜在MoE架构,可显贵裁汰显存需求,加速教化程度,提高模子质地。
这两款更高性能模子,将是来岁开源社区期待的要点家具。
除了整套前沿绽开模子外,英伟达还发布了面向专科AI智能体开导者的教化数据集与前沿强化学习库齐集,多地方助力构建高精度、高效的专科AI智能体。
值得热诚的是,英伟达并不单是追求基准测试得益,而是通过开源绽开,将教化数据、强化学习环境、教化代码等倾囊放出,但愿更多开导者得以应用更优质的数据构建更好的模子,大幅裁汰开导门槛。
Nemotron 3模子权重根据英伟达绽开模子许可契约公开导布。英伟达的合成预教化语料库(近10万亿个token)可供查阅或再行应用。开导者还不错探访Nemotron GitHub代码库中的详备教化和教化后处理有蓄意,从而完毕透顶的可复现性和自界说性。
此外,英伟达当天告示收购AI开源使命负载料理系统提供商SchedMD。SchedMD由Slurm软件开导东说念主员Morris “Moe” Jette和Danny Auble于2010年在好意思国加州利弗莫尔创立。其提供开源的Slurm工夫,可匡助安排可能占用数据中心行状器容量很大一部分的大型计较功课。
英伟达称将不时以开源款式分发SchedMD的软件,英伟达与SchedMD联手正在加强开源软件生态系统,以促进九行八业、各个界限的高性能计较和AI改变。
一、多项基准测试分数超30B Qwen3和20B GPT-OSSNemotron 3系列的首款家具Nemotron 3 Nano,专为DGX Spark、H100和B200 GPU联想,完毕了高蒙眬量效力。
孤独AI基准测试机构Artificial Analysis评定该模子为同等界限模子中兼具极高绽开性和效力及高精度的模子。
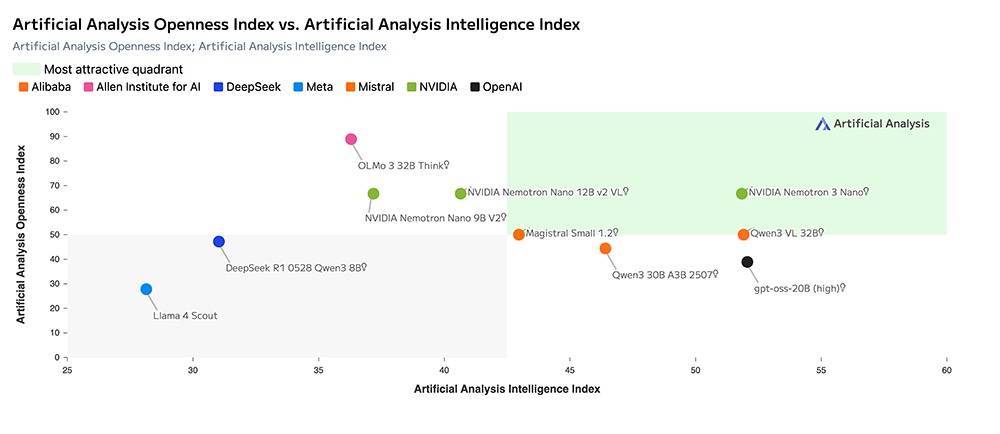
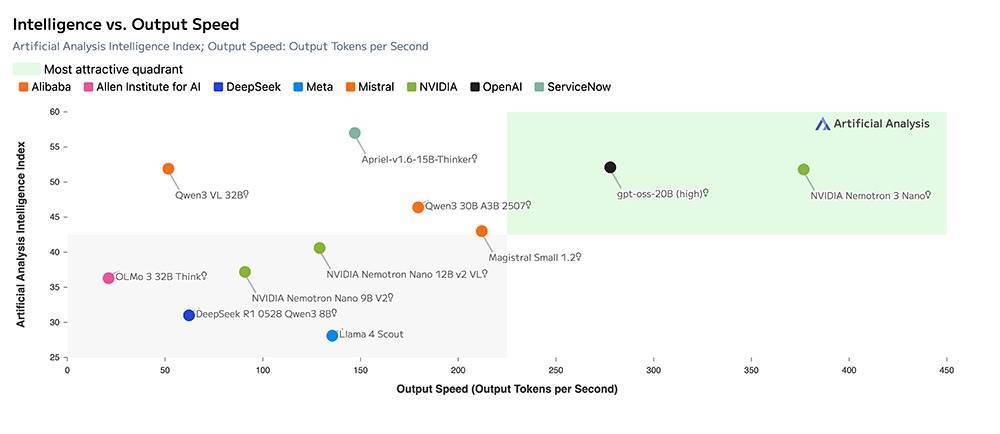
根据Nemotron 3 Nano工夫讲明注解,比较同样界限的Qwen3-30B-A3B-Thinking-2507和GPT-OSS-20B模子,Nemotron 3 Nano在多个基准测试中完毕了同等或更好的精度。

在大大宗通用知识、代码、数学、知识剖析,阅读剖析,多言语和长高下文基准中,Nemotron 3 Nano均取得了高于Qwen3-30B-A3B-Base模子的分数。

在数学和科学推理、编程、智能体器具使用、辅导衔命、永远高下文剖析和多言语才略等详尽性能评估中,Nemotron 3 Nano在通盘类别均卓越了GPT-OSS 20B和Qwen3-30B-A3B-Thinking-2507。

在推理基准上,Nemotron 3 Nano卓越了Qwen3模子,并与之前在这些类别中最佳的模子GPT-OSS并排。在智能体、聊天和长高下文类别中,Nemotron 3 Nano显贵优于其他两种模子。
Nemotron系列模子的早期用户包括埃森哲、Cadence、CrowdStrike、Cursor、德勤、安永、Oracle Cloud Infrastructure、Perplexity、ServiceNow、西门子、新想科技和Zoom。他们正将Nemotron系列模子集成到制造、收集安全、软件开导、媒体、通讯等行业的AI使命流中。
该模子已上线多个企业级AI与数据基础设施平台,包括Couchbase、DataRobot、H2O.ai、JFrog、Lambda及UiPath。
此外,Nemotron 3 Nano将通过Amazon Bedrock(无行状器模式)在亚马逊云科技(AWS)平台上提供给使用公有云的客户,何况也行将补助Google Cloud、Coreweave、Crusoe、Microsoft Foundry、Nebius、Nscale及Yotta。
Nemotron 3 Nano同期以NVIDIA NIM模式提供,可在NVIDIA加速基础设施上进行安全、可扩展的部署,具有极高的秘密性与可控性。
二、夹杂Mamba-Transformer、多环境强化学习教化、4位NVFP4教化英伟达意在打造出更实用的模子,这在其模子联想中可见一斑。
1、夹杂Mamba-Transformer
Nemotron 3将三种架构集成到一个单一的骨干网中:
用于高效序列建模的Mamba层;用于精确推理的Transformer层;MoE路由完毕可扩展的计较效力。Mamba擅长以最小的内存支出追踪长距离依赖联系,即使处理数十万个token也能保抓抓续的性能。Transformer层通过良好的把稳力机制对此进行补充,这些机制不错拿获代码操作、数学推理或复杂方向等任务所需的结构和逻辑联系。
MoE组件在不增多密集计较资本的情况下,显贵擢升了有用参数数目。每个token仅激活一部分群众,从而裁汰蔓延并提高蒙眬量。这种架构尤其适用于智能体集群,因为在集群中,很多轻量级智能体需要并发开动——每个智能体生成方向、检查高下文或膨胀基于器具的使命流。

▲Nemotron 3夹杂架构。该模子将Mamba-2和MoE层与一丝自把稳力层交错罗列,在保抓最先进准确率的同期,极大收尾地提高了推理蒙眬量。
Nemotron 3 Nano使用25T个token进行教化,batch size为3072,并经受Warmup-Stable-Decay(WSD)学习率调遣计谋,其中包含8B个token的学习率预热阶段,峰值学习率为1e-3,最小学习率为1e-5。
模子共有52层,其中23层为MoE层,23层为Mamba-2层,其余6层使用分组查询把稳力机制(GQA),分为2个组。每个MoE层包含128个群众和1个分享群众,每个token激活6个群众。
该模子共有35亿个活跃参数和300亿个总参数,补助英语、德语、西班牙语、法语、意大利语和日语,使用Qwen进行了改变。
这一联想使其token蒙眬量较Nemotron 2 Nano最高擢升4倍,并减少了多达60%的推理token生成量,大大裁汰了推理资本。

▲Nemotron 3 Nano架构
2、多环境强化学习教化
为了使Nemotron 3更迫临果然的智能体行动,英伟达使用一个用于构建和扩展强化学习环境的开源库NeMo Gym在多种环境中对模子进行后教化。这些环境评估模子膨胀一系列动作的才略。
这种基于轨迹的强化教化门径概况生成在多模式使命经由中证实可靠的模子,减少推理漂移,并处千里着恬逸能体管说念中常见的多样结构化操作。
这些环境和强化学习数据集,连同NeMo Gym,都是开源的。开导者可在为特定界限任务定制模子时,重用、扩展以致创建我方的环境。
3、100万token高下文长度
Nemotron 3的百万级高下文容量,具有更强的记念才略,在处理万古辰多模式任务时能更精确地有关信息,补助对大型代码库、长文档、扩展对话和团聚检索本体进行抓续推理。
智能体不再依赖碎屑化的分块启发式门径,而是不错将完竣的凭证集、历史缓冲区和多阶段方向保存在单个高下文窗口中。
其夹杂Mamba-Transformer架构概况高效地处理超大型序列,完毕长高下文窗口。MoE路由也裁汰了每个token的计较量,使得在推理时处理这些大型序列成为可能。
不外由于Hugging Face竖立中VRAM条件较高,默许高下文大小为256k。
4、潜在MoE(latent MoE)
Nemotron 3 Super和Ultra引入了潜在MoE,其中群众在将输出投影回token空间之前,先对分享的潜在暗示进行操作。
这种门径使得模子概况在换取的推理资本下调用4倍的群众,从而更好地针对秘密的语义结构、界限抽象或多跳推理模式进行有利化。

▲圭表MoE与潜在MoE架构对比。在潜在MoE中,token被投影到更小的潜在维度进行群众路由和计较,从而裁汰通讯资本,同期补助更多群众并提高每字节的准确率。
5、多token预测(MTP)
MTP使模子概况在一次前向传播中预测多个改日token,显贵提高长推理序列和结构化输出的蒙眬量。
关于方向、轨迹生成、扩展想维链或代码生成,MTP可裁汰蔓延并提高智能体的反馈速率。

▲多token预测,同期预测多个改日token,在教化时间将准确率提高约2.4%,同期在推理时完毕筹谋性解码速率的擢升。
6、NVFP4教化
Super和Ultra模子均经受NVFP4模式进行预教化。NVFP4是英伟达的4位浮点模式,可在教化和推理方面提供一流的资本精度比,可显贵裁汰显存需求并加速教化程度。
英伟达为Nemotron 3联想了更新的NVFP4算法,以确保在其25T token预教化数据集上完毕准确雄厚的预教化。预教化时间的大部分浮点乘加运算均经受NVFP4模式。
这种效力使更大界限模子能在现存基础设施上进行教化,不会因更高精度模式而罢休准确性。
三、推出全新绽开器具与数据,用于AI智能体定制NVIDIA还发布了面向专科AI智能体开导者的教化数据集与前沿强化学习库齐集,往日所未有的透明度展现了高性能、实在赖的模子是奈何构建的。
3万亿token界限的全新Nemotron预教化、后教化及强化学习数据集,为开导高性能特定界限智能体提供了丰富的推理、编码及多模式使命流规范。
emotron Agentic Safety数据集则提供果然场景的遥测数据,匡助团队评估并擢升复杂智能体系统的安全性。
新数据集亮点包括:
emotron预教化:3万亿个token的数据集,对代码、数学和推理的笼罩范围更广,并通过合成增强和标注管说念得到增强。emotron后教化3.0:包含1300万个样本的语料库,用于监督微融合强化学习,为 Nemotron 3 Nano的对都和推理提供补助。emotron-RL数据集:精选的强化学习数据集和环境齐集,用于器具使用、方向和多模式推理。emotron智能体安全数据集:包含近11000个AI智能体使命经由轨迹的齐集,旨在匡助究诘东说念主员评估和松开智能体系统中新出现的安全风险。为加速开导程度,英伟达发布了eMo Gym与NeMo RL开源库,为Nemotron模子提供教化环境及后教化基础,同期还推出用于考证模子安全性和性能的NeMo Evaluator。
汇聚英伟达NeMo Gym、RL、Data Designer和Evaluator等开源库,上述开源数据集使开导者概况教化、增强和评估他们我方的Nemotron模子。
这些器具及数据集已上线GitHub和Hugging Face平台。
Nemotron 3已获取LM Studio、llama.cpp、SGLang和vLLM补助。此外,Prime Intellect与Unsloth正将NeMo Gym的即用型教化环境径直集成至其使命流,使团队概况愈加速速、粗浅地获取坚韧的强化学习教化才略。
同期,英伟达保重着一个开源的Nemotron GitHub代码库,其中包括:
预教化有蓄意(已提供)展示了Nemotron 3 Nano的教化款式;用于多环境优化的强化学习对都门径;数据处理经由、分词器竖立和长高下文种植;改日的更新将包括更多教化后疗养和微调的配方。GitHub存储库提供了文档、竖立和器具,可端到端地重现要害模式。
使用英伟达的绽开资源,用户不错开动模子、部署模子、检查模子的构建款式,以及教化我方的模子。
四、四个阶段教化门径公开英伟达已表示NVIDIA-Nemotron-3-Nano-30B-A3B-BF16模子的教化门径。
该模子使用英语以偏激他19种言语和43种编程言语进行教化。其数据源涵盖多种文档类型,如网页、对话、著作和其他书面材料,语料库波及法律、数学、科学、金融等多个界限。
为了提高模子准确率,英伟达还加入了一小部分问答和对都类型的数据。该模子使用约25万亿个token进行教化。
该模子的的后教化语料库包含高质地的精选数据和合成数据。后教化使用的主要言语包括英语、德语、西班牙语、法语、意大利语和日语。
第一阶段:预教化
NVIDIA-Nemotron-3-Nano-30B-A3B-Base-BF16模子使用爬取和合成的代码、数学、科学和通用知识数据进行预教化。所非凡据集均在Hugging Face上表示。预教化语料库的大部分已发布在Nemotron-Pre-Training-Datasets数据荟萃。
预教化所用软件:Megatron-LM
第二阶段:监督式微调
该模子在合成代码、数学、科学、器具调用、辅导膨胀、结构化输出和通用知识数据上进行了进一步的微调。所非凡据集均已公开。微调语料库的主要部分已发布在Nemotron-Post-Training-v3数据荟萃。
用于监督式微调的软件:Megatron-LM
第三阶段:强化学习
该模子在数学、代码、科学、辅导侍从、多模式器具使用、多轮对话和结构化输出等多种环境下,经受同步GRPO(群体相对计谋优化)进行多环境强化学习。对话质地通过使用生成式奖励模子的RLHF进一步擢升。
所非凡据集均在本文档的“教化、测试和评估数据集”部分中公开。强化学习环境和数据集已当作NeMo Gym的一部分发布。
用于强化学习的软件:NeMo RL、NeMo Gym
第四阶段:教化后量化
包含KV缓存的模子被量化为FP8。为了在提高效力的同期保抓准确性,英伟达经受了选拔性量化计谋,将把稳力层和输入到这些把稳力层的Mamba层保留为BF16。
用于量化的软件:模子优化器
NVIDIA-Nemotron-3-Nano-30B-A3B-FP8模子是上述使命的效力。完竣的端到端教化有蓄意可在NVIDIA Nemotron开导者代码库中找到。评估终结可使用NeMo Evaluator SDK进行复现。
结语:对准多智能体系统,追求透明与高效“绽开改变是AI卓越的基础。通过Nemotron,咱们将先进AI转换成绽开平台,为开导者提供构建大界限代理式系统所需的透明度与效力。”英伟达首创东说念主兼CEO黄仁勋说。
跟着企业从单模子对话机器东说念主转向融合式多智能体AI系统,开导者面对通讯支出、高下文漂移和高推理资本等挑战。此外,开导者需要模子具备透明度,才气信任其用于自动化复杂使命流。
Nemotron 3绽开模子则直面这些挑战,提供开导专科化代理式AI所需的性能与绽开性,使初创公司概况更快开导和迭代AI智能体,并加速从原型到企业级部署的改变程度。
单一使命流中,在前沿模子与Nemotron之间进行任务路由,不仅能提供更坚韧的智能体,还不错优化token经济效益。
英伟达不单是是把眼神放在单个模子上,而是押注于更重大的智能体系统。要能对这些系统委以信任,绽开、透明、可检查的基础架构至关艰巨。
Mayfield料理合资东说念主Navin Chaddha合计九游体育app娱乐,英伟达的绽开模子堆栈与NVIDIA初创加速方向为初创公司提供了各样模子、器具及经济高效的基础设施,助力其开展训导、完毕相反化发展并快速扩展界限。Nemotron 3不错让首创东说念主在构建代理式AI应用和AI队友方面取得先机,并匡助他们应用NVIDIA重大的用户基础。
